Projets
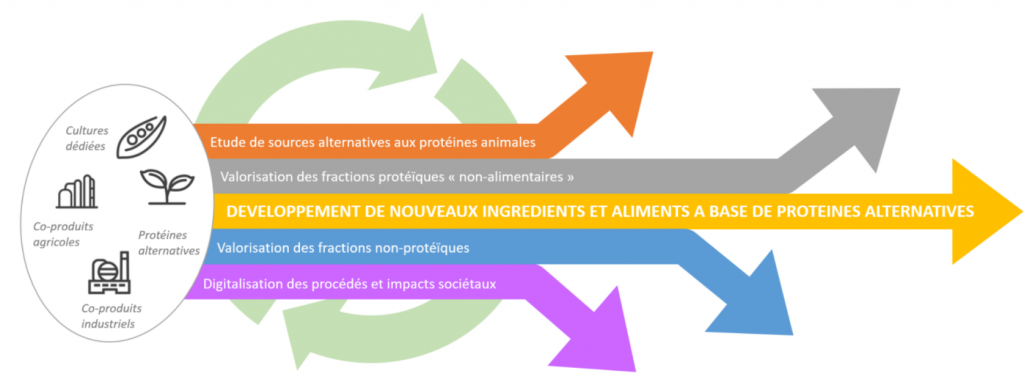

WAL'PROT
Déploiement de la filière des protéines végétales et alternatives en Wallonie

DECHENE
Evaluation de l’implication potentielle de bactéries dans le dépérissement du chêne en Wallonie

ISAC+
Mettre en place une cellule « indicateurs » du PWRP regroupant l’expertise développée en Wallonie

Protection des Riverains
Développer une boîte à outils reprenant les moyens et techniques d’atténuation de l’exposition des riverains aux Produits de Protection des Plantes (PPP) ainsi qu’un outil d’aide à...


BIOAG-FOR-WAL – Pathologie
Mise en place d’un outil de diagnostic large spectre des Phytophthora de la rhizosphère forestière

PRIOR'eau, comment et où agir pour la ressource en eau
Le projet se veut un appui pour cibler la protection de la ressource en eau face aux pollutions par les pesticides.

SIMONE : Innovations systémiques accompagnées d'une évaluation des performances multiples dans le cadre d'expérimentations à la ferme
Le projet SIMONE a pour but d’identifier, fournir et évaluer des innovations qui impliquent des dimensions techniques, environnementales et économiques.

PHYTORE² : Développer un réseau d'exploitants/producteurs exemplaires dans le domaine de la réduction de l'utilisation des produits phytopharmaceutiques
Co-construire avec un réseau de douze agriculteurs des trajectoires de transitions vers une réduction d’utilisation des produits phytopharmaceutiques.


Brochures et dossiers
Nos publications techniques, nos documents thématiques